

Published on Sep 19, 2023
The Page-Rank System of the Needle Search Engine is designed and implemented using Cluster Rank algorithm, which is similar to famous Google's PageRank algorithm.
Google's PageRank algorithm is based on the link structure of the graph. A "WebGraph" package is used to represent the graph in most efficient manner, which helps in accelerating the ranking procedure of the World Wide Web.
Two latest Page-Rank algorithms called Source Rank, Truncated PageRank are taken to compare the existing ranking system, which is Cluster Rank , and deploy the best in the Needle Search Engine.
Two attributes are taken in to consideration for selecting the best algorithm. The first one is the time and second one is human evaluation for the quality of the search. A survey is conducted with the help of the research team on finding the best algorithm on different search topics .
The existing Page-Rank system of the Needle Search Engine takes long update time as the number of URLs increases. Research was done on the published ranking system papers, and below are the details of those papers.
There is a paper called "Efficient Computation of page-rank" written by Taher H.Haveliwala. This paper discusses efficient techniques for computing Page-Rank, a ranking metric for hypertext documents and showed that the Page-Rank can be computed for very large sub graphs of the Web on machines with limited main memory.
They discussed several methods for analyzing the convergence of Page-Rank based on the induced ordering of pages.
The main advantage of the Google's PageRank measure is that it is independent of the query posed by user, this means that it can be pre computed and then used to optimize the layout of the inverted index structure accordingly.
However, computing the Page-Rank requires implementing an iterative process on a massive graph corresponding to billions of Web pages and hyperlinks.
There is a paper written by Yen-Yu Chen and Qingqing gan on Page-Rank calculation by using efficient techniques to perform iterative computation. They derived two algorithms for Page-Rank and compared those with two existing algorithms proposed by Havveliwala], and the results were impressive.
In this paper, the authors namely Lawrence Page, Sergey Brin, Motwani and Terry Winograd took advantage of the link structure of the Web to produce a global "importance" ranking of every Web page.
This ranking, called PageRank, helps search engines and users quickly make sense of the vast heterogeneity of the World Wide Web.
This paper introduces a family of link-based ranking algorithms that propagate page importance through links. In these algorithms there is a damping function that decreases with distance, so a direct link implies more endorsement than a link through a long path.
PageRank is the most widely known ranking function of this family. The main objective of the paper is to determine whether this family of ranking techniques has some interest per se, and how different choices for the damping function impact on rank quality and on convergence speed.
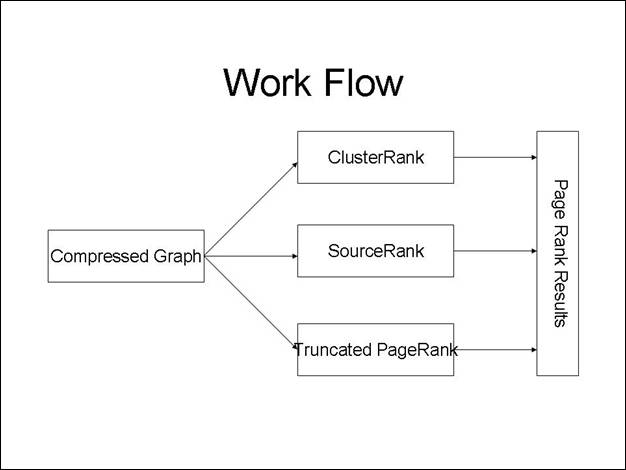
The Page Rank is computed similar to Google's PageRank, except that the supporters that are too close to a target node, do not contribute to wards it ranking. Spammers can afford spam up to few levels only. Using this technique, a group of pages that are linked together with the sole purpose of obtaining an undeservedly high score can be detected.
The authors of this paper apply only link-based methods that are they study the topology of the Web graph with out looking at the content of the web pages.