

Published on May 29, 2026
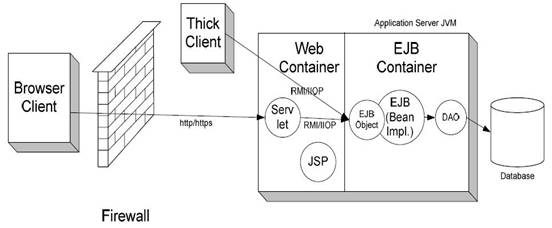
Modern client-server distributed computing systems may be seen as implementations of N-tier architectures. Typically, the first tier consists of client applications containing browsers, with the remaining tiers deployed within an enterprise representing the server side; the second tier (Web tier) consists of web servers that receive requests from clients and pass on the requests to specific applications residing in the third tier (middle tier) consisting of application servers where the computations implementing the business logic are performed; and the fourth tier (database/back-end tier) contains databases that maintain persistent data for applications. Applications in this architecture are typically structured as a set of interrelated components hosted by containers within an application server.
Various services required by applications, such as transaction, persistence, security, and concurrency control, are provided via the containers, and a developer can simply specify the services required by components in a declarative manner.
This architecture also allows flexible configuration using clustering for improved performance and scalability. Availability measures, such as replication, can be introduced in each tier in an application-specific manner. In a typical n-tier system, the interactions between clients and the web tier are performed across the Internet.
The infrastructures supporting these interactions are generally beyond the direct control of an application service provider.
The middle and the database tiers are the most important, as it is on these tiers that the computations are performed and persistency provided.
These two tiers are considered in this paper. Data as well as object replication techniques have been studied extensively in the literature, so our task is not to invent new replication techniques for components, but to investigate how existing techniques can be migrated to components.
Component-oriented middleware infrastructure provides clear separation between components that have persistent state and those that do not.
Therefore, it is natural to divide the replication support for these components into two categories: state replication and computation replication.
State replication deals with masking data store failures to make persistent data highly available to components, while computation replication deals with masking application server failures where the computations are performed.
We examine how an application server can be enhanced to support replication for availability so that components that are transparently using persistence and transactions can also be made highly available, enabling a transaction involving EJBs to commit despite a finite number of failures involving application servers and databases.
The Model-View-Controller (MVC) design pattern was originally brought forward by Trygve Reenskaug and applied in the SmallTalk-80 environment for the first time, the purpose of it is to implement a dynamic software design which simplifies the maintenance and extension of the software application.
MVC seeks to break an application into different parts and define the interactions between these components, thereby limiting the coupling between them and allowing for each one to focus on its responsibilities without worrying about the others.
MVC consists of three categories of the components: Model, View and Controller. This means that it separates the input, processing, and output for the applications and constructs them into a Model-View-Controller three tier structure