

Published on May 29, 2026
Although every person on our planet is built from the same blueprint, no two people are exactly the same. While we are similar enough to readily distinguish ourselves from other living creatures we also celebrate our individual uniqueness.
So what is it that makes us all human, yet unique? Our DNA.
Our DNA (Deoxyribo Nucleic Acid) is found in the nucleus of every cell in our body (apart from red blood cells, which don’t have a nucleus). DNA is a long molecule, made up of lots of smaller units. To make a DNA molecule you need:
nitrogenous bases—there are four of these: adenine (A), thymine (T), cytosine (C), guanine (C)
carbon sugar molecules
phosphate molecules
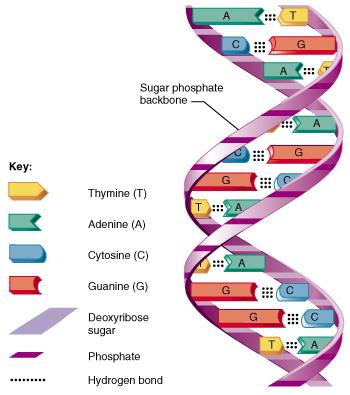
If you take one of the four nitrogenous bases, and put it together with a sugar molecule and a phosphate molecule, you get a nucleotide base. The sugar and phosphate molecules connect the nucleotide bases together to form a single strand of DNA. Two of these strands then wind around each other, making the twisted ladder shape of the DNA double helix. The nucleotide bases pair up to make rungs of the ladder, and the sugar and phosphate molecules make the sides. The bases pair up together in specific combinations: A always pairs with T, and C always pairs with G to make base pairs. Put three billion of these base pairs together in the right order, and you have a complete set of human DNA—the human genome. This amounts to a DNA molecule about a metre long. It’s the order in which the base pairs are arranged—their sequence—in our DNA that provides the blueprint for all living things and makes us what we are.
The DNA sequence of the base pairs in a fish’s DNA is different to those in a monkey. The base pair sequence of all people is nearly identical—that’s what makes us all humans. However, there are small differences in the order of the three billion base pairs in everyone’s DNA that cause the variations we see in hair colour, eye colour, nose shape etc. No two people have exactly the same DNA sequence (except for identical twins, because they came from a single egg that split into two, forming two copies of the same DNA). We get our DNA from our parents. The DNA of the human genome is broken up into 23 pairs of chromosomes (46 in total). We receive 23 from our mother and 23 from our father. Egg and sperm cells have only one copy of each chromosome so that when they come together to form a baby, the baby has the normal 2 copies. Three billion is a lot of base pairs, and together they contain an enormous amount of information.

Working out the sequence of the base pairs in all our genes enables us to understand the code that makes us who we are. This knowledge can then give us clues on how we develop as embryos, why humans have more brainpower than other animals and plants, and what happens in the body to cause cancer. But establishing the sequence of three billion base pairs is a BIG task. The great and ambitious research program that sought to do this was called the Human Genome Project.
The idea of the Human Genome Project was born in the 1970s, when scientists learned how to ‘clone’ small bits of DNA, around the size of a gene. To clone DNA, scientists cut out a fragment of human DNA from the long strand and then incorporate it into the genome of a bacteria, or a bacterial virus. The fragment is then is replicated within the bacterial cell many times and every time the bacterial cell divides, the new cells also contain the introduced Francis Collins, former director of the National Human Genome Research Institute, led the Human Genome Project.
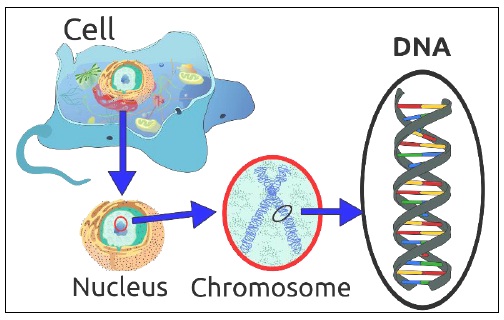
A cell in human body is simply invisible to naked eye, Microscopes are essential to view them. A Human DNA which is about 2m long gets packed so well that it fits into cell nucleus, then think of the difficulty in viewing a DNA D DNA fragment.
Bacterial cells reproduce prolifically, and so this process ends up making millions of cells that all contain the introduced DNA fragment, enough that researchers can study it in detail and figure out the sequence of the base pairs. With time, researchers have been able to study an ever greater number of different DNA fragments, that is, different genes. It became clear that certain variant DNA sequences were associated with particular conditions: diseases such as cystic fibrosis or breast cancer, or normal, non-harmful variants like red hair.
There was initially a lot of opposition to the Human Genome Project, even from some scientists. Considering only around 1.5 per cent of our genome is actual genes that code for proteins, it was thought that much of the $3 billion cost to sequence the entire human genome would be wasted on the ‘junk’ DNA that scientists thought didn’t get used. The important role the ‘junk’ DNA plays in gene regulation wasn’t yet appreciated. Research groups in many countries, including Australia, began to sequence different genes, providing the beginnings of a total human gene map. In 1989, the Human Genome Organization (HUGO) was found by leading scientists to coordinate the massive International effort involved in collecting sequence data to unravel the secrets of our genes.
The Human Genome Project aimed to map the entire genome, including the position of every human gene along the DNA strand, and then to determine the sequence of each gene’s base pairs. At the time, sequencing even a small gene could take months, so this was seen as a stupendous and very costly undertaking. Fortunately, biotechnology was advancing rapidly, and by the time the project was finishing it was possible to sequence the DNA of a gene in a few hours. Even so, the project took ten years to complete; the first draft of the human genome was announced in June 2000.
In February 2001, the publicly funded Human Genome Project and the private company Celera both announced that they had mapped virtually all of the human genome, and had begun the task of working out the functions of the many new genes that were identified. Scientists were surprised to find that humans only have around 25,000 genes, not much more than the roundworm Caenorhabditis elegans, and less than a tiny water crustacean called Daphnia, which has around 30,000. However, genome sequencing was making it clear that an organism's complexity is not necessarily related to its number of genes.
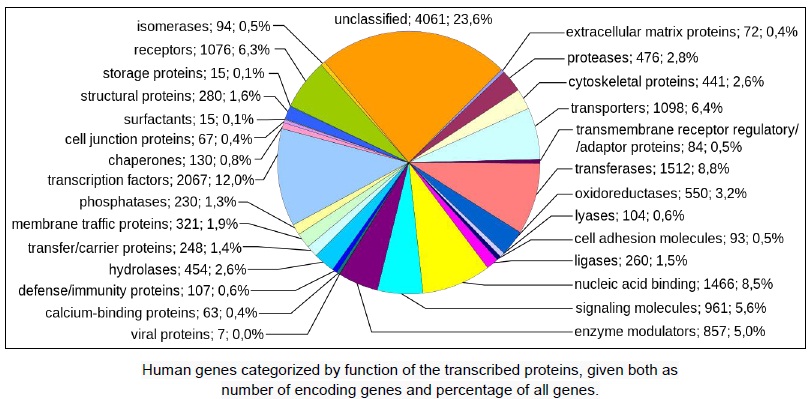
Also, while we might have a surprisingly small number of genes, they are often expressed in multiple and complex ways. Numerous genes have as many as a dozen different functions and may be translated into several different versions active in different tissues. We also have a lot of extra DNA that doesn’t make up specific genes. So even though the puffer fishTetraodon nigroviridis has more genes than we do—nearly 28,000—the size of its entire genome is actually only around one tenth of ours as it has much less of the non-coding DNA. In April 2003, the 50th anniversary of the publication of the structure of DNA, the complete final map of the Human Genome was announced. The DNA from a large number of donors, women and men from different nations and of different races, contributed to this ‘typical’ Human Genome Sequence.
The process of identifying the boundaries between genes and other features in a raw DNA sequence is called genome annotation and is in the domain of bioinformatics. While expert biologists make the best annotators, their work proceeds slowly, and computer programs are increasingly used to meet the high-throughput demands of genome sequencing projects. Beginning in 2008, a new technology known as RNA-seq was Introduced that allowed scientists to directly sequence the messenger RNA in cells. This replaced previous methods of annotation, which relied on inherent properties of the DNA sequence, with direct measurement, which was much more accurate.

Today, annotation of the human genome and other genomes relies primarily on deep sequencing of the transcripts in every human tissue using RNA-seq. These experiments have revealed that over 90% of genes contain at least one and usually several alternative splice variants, in which the exons are combined in different ways to produce 2 or more gene products from the same locus. The genome published by the HGP does not represent the sequence of every individual's genome. It is the combined mosaic of a small number of anonymous donors, all of European origin. The HGP genome is a scaffold for future work in identifying differences among individuals. Subsequent projects sequenced the genomes of multiple distinct ethnic groups, though as of today there is still only one "reference genome.
Key findings of the draft (2001) and complete (2004) genome sequences include:
1. There are approximately 22,300 protein-coding genes in human beings, the same range as in other mammals.
2. The human genome has significantly more segmental duplications (nearly identical, repeated sections of DNA) than had been previously suspected. At the time when the draft sequence was published fewer than 7% of protein families appeared to be vertebrate specific.
The Human Genome Project was started in 1990 with the goal of sequencing and identifying all three billion chemical units in the human genetic instruction set, finding the genetic roots of disease and then developing treatments. It is considered a Mega Project because the human genome has approximately 3.3 billion base-pairs. With the sequence in hand, the next step was to identify the genetic variants that increase the risk for common diseases like cancer and diabetes. It was far too expensive at that time to think of sequencing patients’ whole genomes. So the National Institutes of Health embraced the idea for a "shortcut", which was to look just at sites on the genome where many people have a variant DNA unit.
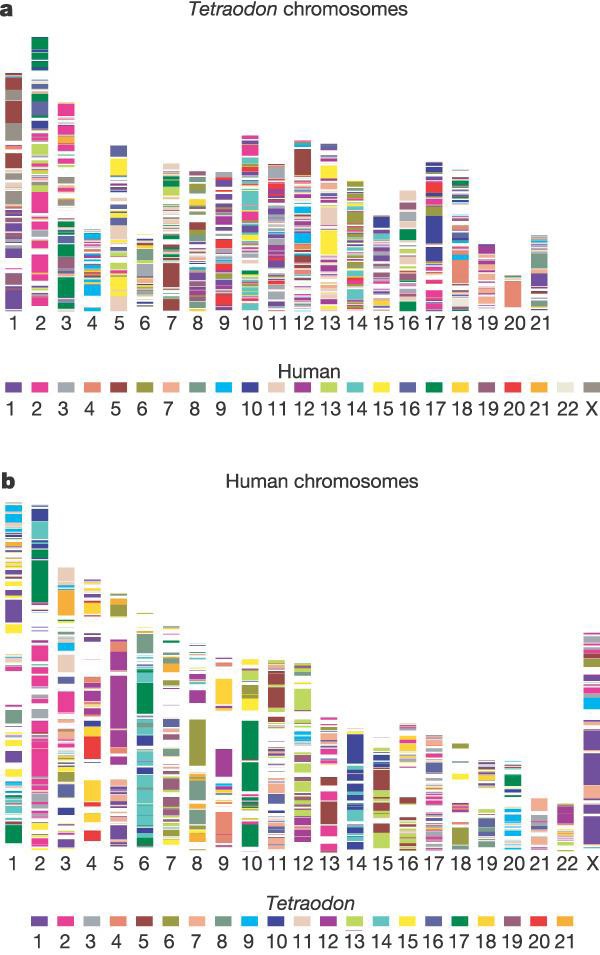
A, For each Tetraodon chromosome, coloured segments represent conserved synteny with a particular human chromosome. Synteny is defined as groups of two or more Tetraodon genes that possess an orthologue on the same human chromosome, irrespective of orientation or order. Tetraodon chromosomes are not in descending order by size because of unequal sequence coverage. The entire map includes 5,518 orthologues in 900 syntenic segments. B, On the human genome the map is composed of 905 syntenic segments. See Supplementary Information for the synteny map between Tetraodon and mouse
The theory behind the shortcut was that, since the major diseases are common, so too would be the genetic variants that caused them. Natural selection keeps the human genome free of variants that damage health before children are grown, the theory held, but fails against variants that strike later in life, allowing them to become quite Common. (In 2002 the National Institutes of Health started a $138 million dollar project called the Hap Map to catalog the common variants in European, East Asian and African genomes.) The genome was broken into smaller pieces; approximately 150,000 base pairs in length. These pieces were then ligated into a type of vector known as "bacterial artificial chromosomes", or BACs, which are derived from bacterial chromosomes which have been genetically engineered. The vectors containing the genes can be inserted into bacteria where they are copied by the bacterial DNA replication machinery.
Each of these pieces was then sequenced separately as a small "shotgun" project and then assembled. The larger, 150,000 base pairs go together to create chromosomes. This is known as the "hierarchical shotgun" approach, because the genome is first broken into relatively large chunks, which are then mapped to chromosomes before being selected for sequencing. Funding came from the US government through the National Institutes of Health in the United States, and a UK charity organization, the Wellcome Trust, as well as numerous other groups from around the world.
At the onset of the Human Genome Project several ethical, legal, and social concerns were raised in regards to how increased knowledge of the human genome could be used to discriminate against people. One of the main concerns of most individuals was the fear that both employers and health insurance companies would refuse to hire individuals or refuse to provide insurance to people because of a health concern indicated by someone's genes. In 1996 the United States passed the Health Insurance Portability and Accountability Act (HIPAA) which protects against the unauthorized and non-consensual release of individually identifiable health information to any entity not actively engaged in the provision of healthcare services to a patient.

Along with identifying all of the approximately 20,000–25,000 genes in the human genome, the Human Genome Project also sought to address the ethical, legal, and social issues that were created by the onset of the project. For that the Ethical, Legal, and Social Implications (ELSI) program was founded in 1990. Five percent of the annual budget was allocated to address the ELSI arising from the project. This budget started at approximately $1.57 million in the year 1990, but increased to approximately $18 million in the year 2014. Whilst the project may offer significant benefits to medicine and scientific research, some authors have emphasized the need to address the potential social consequences of mapping the human genome. "Molecularising disease and their possible cure will have a profound impact on what patients expect from medical help and the new generation of doctors' perception of illness."
The project was not able to sequence all the DNA found in human cells. It sequenced only "euchromatic" regions of the genome, which make up more than 95% of the genome. The other regions, called "heterochromatic" are found in centromeres and telomeres, and were not sequenced under the project. The Human Genome Project was declared complete in April 2003. An initial rough draft of the human genome was available in June 2000 and by February 2001 a working draft had been completed and published followed by the final sequencing mapping of the human genome on April 14, 2003.
Although this was reported to cover 99% of the euchromatic human genome with 99.99% accuracy, a major quality assessment of the human genome sequence was published on May 27, 2004 indicating over 92% of sampling exceeded 99.99% accuracy which was within the intended goal. Further analyses and papers on the HGP continue to occur.
There is no doubt that information from the Human Genome Project provides huge benefits to human health in helping to understand and treat genetic diseases (such as breast cancer, cystic fibrosis and sickle cell anaemia). However, some people see ethical issues, and wonder if scientists are “playing God” with our genomes. Could genetic information be misused; for example, through genetic discrimination by employers or insurance companies? Most people agree that gene testing can be used ethically to prevent serious diseases such as cancer, or during pregnancy to avoid the birth of someone with a severe handicap, but should we allow gene testing to choose a child who will be able to be better at sports, or more intelligent? What about sex selection, already a problem in some countries? And will it become possible to use genetic information to change genes in children or adults for the better? Do we really want to know if we run the risk of developing a particular disease that may or may not be treatable? What are the privacy issues regarding genome screening on a population scale? Still many more such questions arise and leave us in oblivion of deep thoughts, yet we need to believe in science and its advancements and realize that with NEW KNOWLEDGE COMES HUGE NEW RESPONSIBILITIES.
• HELP FROM INTERNET & Wikipedia
• INFORMATION FROM LIBRARY
• HELP FROM TEACHERS
• Comprhensive Lab Manual J.P.Sharma